
Just for the record, this happens to be one of my favorite interview questions to ask candidates.
At some point in time, there will be a database containing tables without clustered indexes (a heap) that you will be responsible for maintaining. I personally believe that every table should have a clustered index, but sometimes my advice is not always followed. Additionally there can be databases from a 3rd party vendor that have this same design. Depending on the what those heap tables are used for, over time it’s possible they can become highly fragmented and degrade query performance. A fragmented heap is just as bad as a fragmented index. To resolve this issue, I’d like to cover four ways we can defragment a heap.
To start with, we will need a sample database with a highly fragmented heap table. You can use the following script to create the FRAG database. However, depending on your server, it may take 5 to 10minutes to finish each of the INSERT and DELETE statements.
CREATE DATABASE FRAG; GO USE FRAG; GO CREATE TABLE MyTable(col1 int,col2 int) GO CREATE NONCLUSTERED INDEX [idx1] ON [dbo].[MyTable]([col1] ASC) GO CREATE NONCLUSTERED INDEX [idx2] ON [dbo].[MyTable]([col2] ASC) GO SET NOCOUNT ON DECLARE @x INT = 0; DECLARE @maxval INT, @minval INT; SELECT @maxval=1000000,@minval=1; INSERT MyTable SELECT CAST(((@maxval + 1) - @minval) * RAND(CHECKSUM(NEWID())) + @minval AS INT),CAST(((@maxval + 1) - @minval) * RAND(CHECKSUM(NEWID())) + @minval AS INT); GO 500000 SET NOCOUNT ON DECLARE @maxval INT, @minval INT; SELECT @maxval=1000000,@minval=1; DELETE MyTable WHERE col1 = CAST(((@maxval + 1) - @minval) * RAND(CHECKSUM(NEWID())) + @minval AS INT); GO 450000
Now let’s use the sys.dm_db_index_physical_stats DMV to check the fragmentation level.
USE FRAG;
GO
SELECT
index_id
,index_type_desc
,index_depth
,index_level
,avg_fragmentation_in_percent
,fragment_count
,page_count
,record_count
FROM sys.dm_db_index_physical_stats(
DB_ID('FRAG')
,OBJECT_ID('MyTable')
,NULL
,NULL
,'DETAILED');
GO
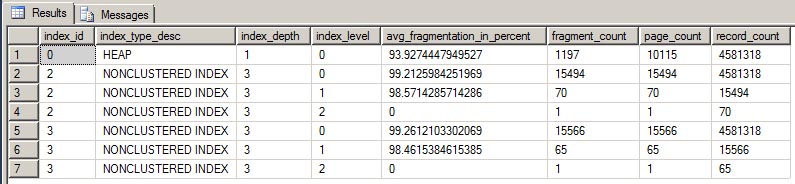
As you can see, the heap is 93% fragmented, and both non-clustered indexes are 99% fragmented. So now we know what we’re dealing with.
Repair options in order of my preference:
- ALTER TABLE…REBUILD (SQL 2008+).
- CREATE CLUSTERED INDEX, then DROP INDEX.
- CREATE TABLE temp, INSERT INTO temp, DROP original table, sp_rename temp to original, recreate the non-clustered indexes.
- BCP out all data, drop the table, recreate the table, bcp data in, recreate the non-clustered indexes.
Option 1 is the easiest and the most optimal way to remove heap fragmentation; however, this option was only introduced in SQL Server 2008, so it’s not available for all versions. This is a single command that will rebuild the table and any associated indexes; yes, even clustered indexes. Keep in mind, this command will rebuild the heap as well as all of the non-clustered indexes.
ALTER TABLE dbo.MyTable REBUILD; GO
Option 2 is almost as quick, but involves a little bit of planning. You will need to select a column to create the clustered index on, keeping in mind this will reorder the entire table by that key. Once the clustered index has been created, immediately drop it.
CREATE CLUSTERED INDEX cluIdx1 ON dbo.MyTable(col1); GO DROP INDEX cluIdx1 ON dbo.MYTable; GO
Option 3 requires manually moving all data to a new temporary table. This option is an offline operation and should be done during off-hours. First you will need to create a new temporary table with the same structure as the heap, and then copy all rows to the new temporary table.
CREATE TABLE dbo.MyTable_Temp(col1 INT,col2 INT); GO INSERT dbo.MyTable_Temp SELECT * FROM dbo.MyTable; GO
Next, drop the old table, rename the temporary table to the original name, and then create the original non-clustered indexes.
DROP TABLE dbo.MyTable; GO EXEC sp_rename ‘MyTable_Temp’,‘MyTable’; GO CREATE NONCLUSTERED INDEX idx1 ON dbo.MyTable(col1); GO CREATE NONCLUSTERED INDEX idx2 ON dbo.MyTable(col2); GO
Option 4 is by far to the least efficient way to complete this task. Just like option 3, this option is an offline operation and should be done during off-hours. First we need to use the BCP utility to bulk copy out all of the data to a data file. Using BCP will require a format file to define the structure of what we’re bulk copying. In this example, I am using an XML format file. More information on format files can be found here.
BCP FRAG.dbo.MyTable OUT D:MyTable.dat -T -STRONTEST1 -fD:MyTableFormat.xml
Once that is complete, we need to drop and recreate the table.
DROP TABLE dbo.MyTable; GO CREATE TABLE dbo.MyTable(col1 INT,col2 INT); GO
Next, we need to use the BCP utility to bulk copy all of the data back into the table.
BCP FRAG.dbo.MyTable IN D:MyTable.dat -T -STRONTEST1 -fD:MyTableFormat.xml
Finally, we can create the original non-clustered indexes.
Options 1 and 2 do not require any downtime for the table; however, they will cause blocking during the rebuild stage. You can use the WITH ONLINE option but that will require enough free space in tempdb for the entire table. Both options 3 and 4 will require downtime and will potentially impact any foreign key constraints or other dependent objects. If you’re running SQL Server 2008 or higher, I highly recommend using option 1.
As you’ve seen, there are multiple ways of dealing with heap fragmentation. However, the best way is to avoid heaps altogether in your database design.


