First introduced in SQL Server 2012, the Columnstore index is a new in-memory feature that allows for the creation of indexes that are stored in a column-wise fashion. It is targeted for data warehouses and can improve query performance by 10 to 100x. A columnstore index stores data in a different type of index page as well as heavily compressing the data. It also introduces a new batch execution mode that greatly increases processing speed and reduces CPU utilization. The combination of the new storage type, the compressed data, and batch mode processing allows SQL Server to read less data and greatly improve query performance.
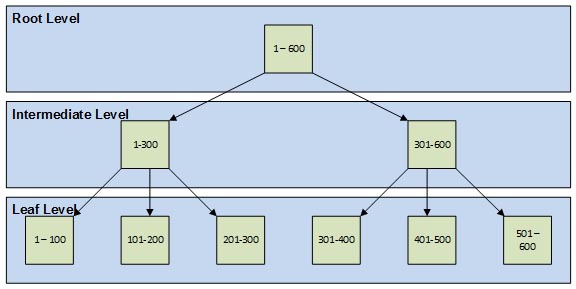
So how does this new index differ from traditional indexes? In all versions prior to 2012, SQL Server uses a B-tree structure (see below) for all indexes, including both clustered and non-clustered.
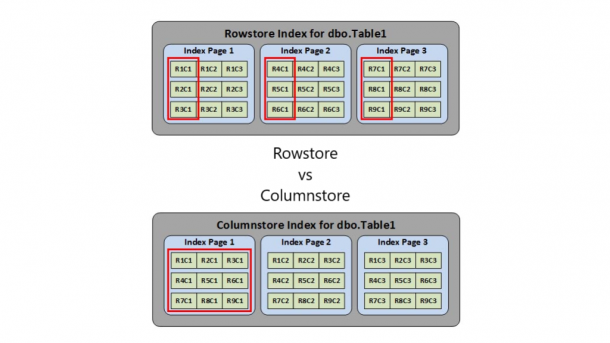
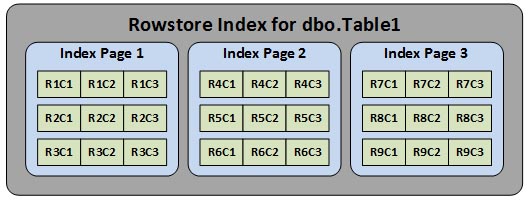
At the leaf level of the B-tree indexes, SQL Server stores the indexed data in a row-wise fashion. So a single index page will store all data from all columns for one or more rows. For example, if we have create an index with three columns (C1, C2, and C3) for dbo.Table1, the internal structure would look something like this.
Index page 1 would store columns C1, C2, and C3 for rows R1, R2 and R3. Index page 2 would store columns C1, C2, and C3 for rows R4, R5 and R6, and so on and so on. This is referred to as a rowstore, because it stores the data in a row-wise fashion.
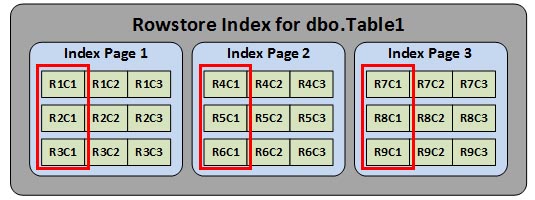
If we were to issue a simple query to select column C1 from the Table1, then SQL Server would need to read all three index pages to get the values from all 9 rows. Each read would be a logical I/O, so a total of 3 logical I/O’s would be needed.
SELECT C1 FROM dbo.Table1;
GO
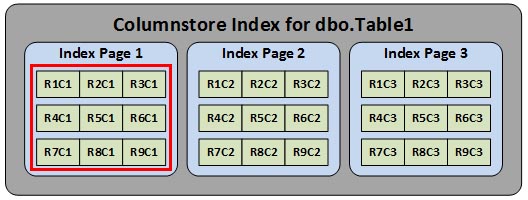
Now if we create a columnstore index on the same data, the logical storage of that data would look something like this.
Index page 1 would store column C1 for rows R1 through R9. Index page 2 would store columns C2 for rows R1 through R9, and so on and so on. This is referred to as a columnstore index, because it stores the data in a column-wise fashon.
If we issued the same query, SQL Server could use the new columnstore index and would only need to read index page 1 to get all the values of column C1 for rows R1 through R9. This results in 1 logical I/O since only a single index page needs to be read.
For this simple query we have a 3x performance improvement. Now 1 I/O vs 3 I/O’s does doesn’t really matter, but remember this feature is targeted at data warehouses that could have tables containing millions or even billions of rows. Once you use columnstore indexes on tables that large, then the performance gains in I/O are much more noticeable.
The second advantage of using columnstore indexes is the data stored within the index is heavily compressed. This compression algorithm is different than row or page compression or even backup compression, and it usually works best for character or numeric data that have a lot of repeating values. Having the data compressed, means SQL Server needs to read fewer pages to return all of the data. Going back to our Table1 example from above, if the indexes were storing lots more data then the layout would really look more like this.
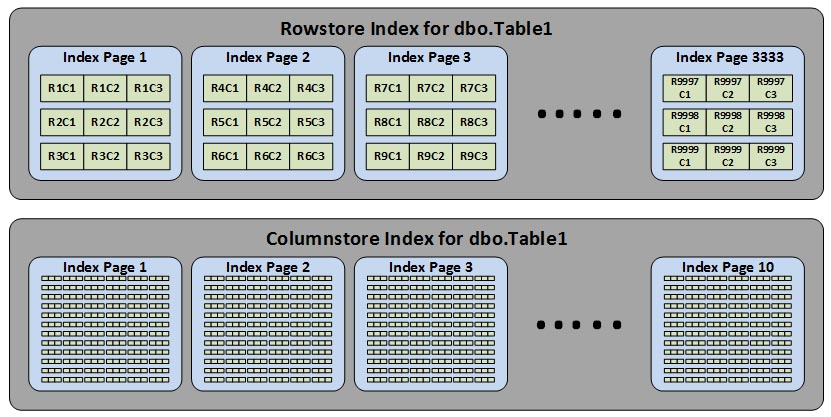
Because of that highly compressed data, the columnstore index might only need a few dozen index pages to store the same amount of data that would normally take a rowstore index several thousand.
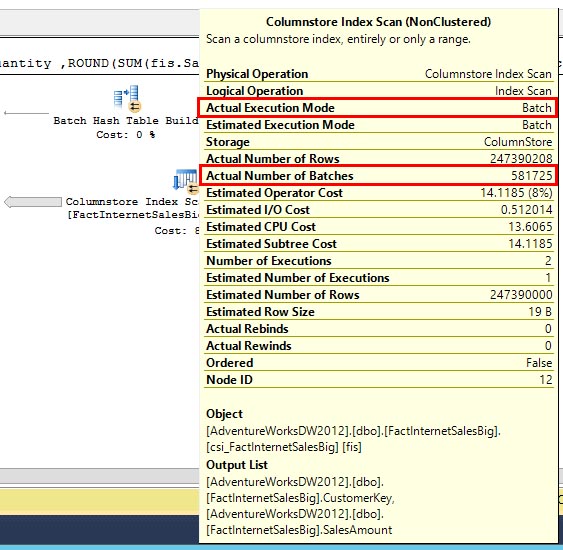
The third way columnstore indexes help improve performance is through the use of batch mode processing. This new execution mode allows the CPU to process approximately 1000 row at a time. This is more efficient for the CPU to process a batch of data instead of one row at a time. The result is faster query processing and lower CPU utilization. In the example query plan below, you can see SQL Server issued 581725 batches to process the ~247 million rows. That’s an average of 425 rows processed per batch.
Creating a columnstore index is as easy as creating any other non-clustered index. Just specify the name of the index, the table, and which columns are to be included. The best practice from Microsoft suggests adding all columns of the base table into the columnstore index. See the example below.
CREATE NONCLUSTERED COLUMNSTORE INDEX csi_FactInternetSales
ON dbo.FactInternetSales
(
ProductKey,
OrderDateKey,
DueDateKey,
ShipDateKey,
CustomerKey,
PromotionKey,
CurrencyKey,
SalesTerritoryKey,
SalesOrderNumber,
SalesOrderLineNumber,
RevisionNumber,
OrderQuantity,
UnitPrice,
ExtendedAmount,
UnitPriceDiscountPct,
DiscountAmount,
ProductStandardCost,
TotalProductCost,
SalesAmount,
TaxAmt,
Freight,
CarrierTrackingNumber,
CustomerPONumber,
OrderDate,
DueDate,
ShipDate
);
GO
All of this is really great news for SQL Server lovers; however, as with all new features, there are usually limitations and columnstore indexes are no exception. Below is a list of some of those restrictions.
- The base table is READ-ONLY.
- The columnstore index cannot be altered; only dropped and recreated.
- The columnstore index cannot be created as clustered index.
- Certain data types cannot be used.
- Cannot include a sparse column.
- Cannot include a column with Filestream data.
- The index cannot act as a primary or foreign key.
- Cannot be combined with replication, change tracking, or change data capture.
- Uses the buffer pool, so columnstore index pages can be flushed from memory.
- Enterprise Edition only
I’m sure the first item on the list got your attention. A limitation that has the base table and all of its data is in a read-only state after creating a columnstore index. Any attempt to change data within the base table (dbo.Table1) will result in an error.
INSERT dbo.Table1 VALUES ('Oscar', 'The new DBA', 'Charlotte, NC');
GO
Msg 35330, Level 15, State 1, Line 1
INSERT statement failed because data cannot be updated in a table with a columnstore index. Consider disabling the columnstore index before issuing the INSERT statement, then rebuilding the columnstore index after INSERT is complete.
This may seem like a huge issue, but in reality it’s not that much of a problem. Keep in mind this feature is targeted at data warehouses that modify data infrequently. Additionally, there are several workarounds for updating or changing data; for example, deleting the columnstore index making the change and then recreating the columnstore index. I’ll cover these workarounds in more detail in a future blog post.
UPDATE: Read my post How to Edit Read-Only Non-clustered Columnstore Data to learn how to work around this issue.
In my opinion, the limitation of the data types is a bigger issue than the data being in a read-only state; that’s because there is no workaround. In essence, this will affect the design of your database. All of these data types are not allowed for use within a columnstore index.
- binary and varbinary
- ntext , text, and image
- varchar(max) and nvarchar(max)
- uniqueidentifier
- rowversion (and timestamp)
- sql_variant
- decimal (and numeric) with precision greater than 18 digits
- datetimeoffset with scale greater than 2
- CLR types (hierarchyid and spatial types)
- xml
If you have an existing data warehouse that you want to use this feature and the tables are littered with uniqueidentifier or XML data types, then you’re only choice is to redesign the database. That’s usually the last thing a development team wants to hear just so they can implement a new database feature. Even if you try to add one of these columns to a columnstore index, SQL Server will throw an error about the restricted data type.
Msg 35343, Level 16, State 1, Line 1
CREATE INDEX statement failed. Column ‘IDNumber’ has a data type that cannot participate in a columnstore index. Omit column ‘IDNumber’.
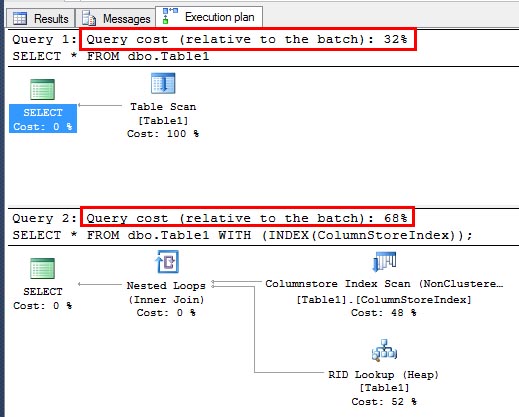
You can still create a columnstore index on the table by excluding the restricted column; however, if queries need data from that column then it could be much more expensive to use the columnstore index than a traditional rowstore index. The following example excluded the IDNumber column from the columnstore index, so the query processor needed to do a row lookup to get that missing data.
SELECT * FROM dbo.Table1;
SELECT * FROM dbo.Table1 WITH (INDEX(ColumnStoreIndex));
GO
As you can see the result of the forced columnstore plan did not fare well against the table scan. Its query cost is nearly twice as high and table scan needed only 1 logical read compared to 38 for the columnstore index.
Another issue you might run into is the amount of available physical memory on the server. SQL Server requires a minimal amount of memory in order to create a columnstore index. This can be calculated as Memory Grant Request in MB = ((4.2 * number of columns in the columnstore index) + 68) * Degree of Parallelism + (number of string columns * 34). If there is not enough physical memory available to create the columnstore index, SQL Server will throw an error.
The statement has been terminated.
Msg 8658, Level 17, State 1, Line 2
Cannot start the columnstore index build because it requires at least 345520 KB, while the maximum memory grant is limited to 84008 KB per query in workload group ‘default’ (2) and resource pool ‘default’ (2). Retry after modifying columnstore index to contain fewer columns, or after increasing the maximum memory grant limit with Resource Governor.
Microsoft did an excellent job of creating a very detailed error message that even includes a few suggestions to avoid this error. One of which is to alter the Resource Governor to allow larger memory grants. However, if that is not an option, then you can use the
MAXDOP hint to reduce the degree of parallelism when creating the columnstore index. By reducing or even removing parallelism, it will reduce the memory grant requirements. I’ll cover these memory workarounds in more detail in a future blog post.
UPDATE: Read my post on Columnstore Memory Grant Issue to learn how to avoid this issue.
Let’s look at some examples that involve a lot more data.
Using the FactInternetSales from the AdventureWorksDW2012 database, I have expanded it to nearly 250 million rows. You can get the code to expand the table from
Kalen Delaney’s blog. We can run the following query to determine the order quantity and total sales grouped by education level.
SELECT
dc.EnglishEducation AS EducationLevel
,COUNT(*) AS OrderQuantity
,CAST(SUM(fis.SalesAmount) AS DECIMAL(15,2)) AS SalesAmount
FROM dbo.FactInternetSales fis
INNER JOIN dbo.DimCustomer dc ON fis.CustomerKey = dc.CustomerKey
GROUP BY dc.EnglishEducation
ORDER BY dc.EnglishEducation
OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX);
GO
This query uses the IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX hint which tells the query optimizer to ignore a columnstore index that might be on this table. In order for SQL Server to process this query, it will need the value of every row for the CustomerKey and SalesAmount columns from that FactInternetSales. The traditional rowstore index will require SQL Server to read every page from the table to get those values. What we get is a query that requires 5934694 logical reads and over 28 minutes of runtime to complete. Run the same query again, but this time remove the hint and allow it use the columnstore index.
SELECT
dc.EnglishEducation AS EducationLevel
,COUNT(*) AS OrderQuantity
,CAST(SUM(fis.SalesAmount) AS DECIMAL(15,2)) AS SalesAmount
FROM dbo.FactInternetSales fis
INNER JOIN dbo.DimCustomer dc ON fis.CustomerKey = dc.CustomerKey
GROUP BY dc.EnglishEducation
ORDER BY dc.EnglishEducation;
GO
What you’ll notice is an almost instantaneous response from SQL Server. SQL Server only needed to do 6822 logical reads from FactInternetSales, and the runtime was reduced to about 4 seconds. That’s over 800x fewer IO’s and about 420x faster runtime.
Workloads that do a lot of table or index scans, such as the example above, will benefit most from using a columnstore index. However, singleton lookups will not perform as well. We can use the same query but this time we’ll specify order numbers starting with a certain value. We’ll also use an index hint WITH (INDEX(csi_FactInternetSales)) to force the query optimizer to use the columnstore index.
SELECT
dc.EnglishEducation AS EducationLevel
,COUNT(*) AS OrderQuantity
,CAST(SUM(fis.SalesAmount) AS DECIMAL(15,2)) AS SalesAmount
FROM dbo.FactInternetSales fis WITH (INDEX(csi_FactInternetSales))
INNER JOIN dbo.DimCustomer dc ON fis.CustomerKey = dc.CustomerKey
WHERE fis.SalesOrderNumber LIKE 'SO437%'
GROUP BY dc.EnglishEducation
ORDER BY dc.EnglishEducation;
GO
Forcing the query optimizer to use the columnstore index was a bad idea in this case. The columnstore index was used, but it had to scan the entire set of data to look for values starting with ‘SO437%’. This resulted in over 1.7 million logical reads and about 68 seconds before returning the results. Now remove the index hint and run the query again.
SELECT
dc.EnglishEducation AS EducationLevel
,COUNT(*) AS OrderQuantity
,CAST(SUM(fis.SalesAmount) AS DECIMAL(15,2)) AS SalesAmount
FROM dbo.FactInternetSales fis
INNER JOIN dbo.DimCustomer dc ON fis.CustomerKey = dc.CustomerKey
WHERE fis.SalesOrderNumber LIKE 'SO437%'
GROUP BY dc.EnglishEducation
ORDER BY dc.EnglishEducation;
GO
We still had to do 11254 logical reads on the rowstore index for the table, but we were able to get the results in less than a second.
As you can see, if your workload meets the requirements, then the benefits of using columnstore indexes far out weight their disadvantages. I highly recommend lots of testing if you intend to implement columnstore indexes. It takes careful planning for loading or modifying data, designing your tables to account for the data type restrictions, and knowing how to write your queries to get the most performance from the columnstore indexes.