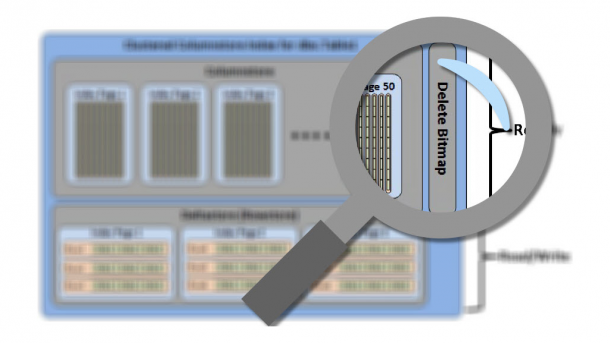
In some of my previous posts, I have talked about how to create Columnstore indexes. Now I’d like to discuss one maintenance detail that you need to keep an eye on. I’m talking specifically about the number of “deleted rows” in a clustered Columnstore index. One of the great benefits of clustered Columnstore indexes in SQL Server 2014 is they are writeable, which means you can insert, update and delete data. This is all well and good, but I think there really should be an asterisk beside update* and delete* with a disclaimer that says something like “Deletes aren’t really...
Continue reading...2014
How to Edit Read-Only Non-clustered Columnstore Data
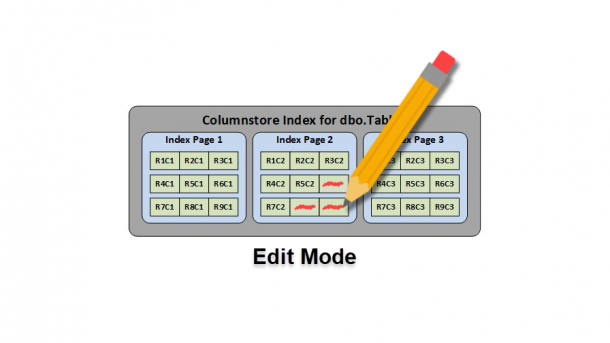
As I’ve discussed in some of my previous posts, creating a non-clustered Columnstore index will make the index as well as the base table read-only. Which means you can’t insert, update, or delete any data until your drop the index. This may seem like a huge issue, but in reality it’s not that much of a problem. Keep in mind the Columnstore index feature is targeted at data warehouses that modify data infrequently. In the examples below, I go through two methods you can use to edit your read-only data. To get started, we need to create a test table...
Continue reading...Columnstore Table Analyzer

As I’ve discussed in some of my previous posts, there are quite a few data types that cannot be part of a Columstore index. While there are fewer restrictions in SQL Server 2014, they still exist. I find myself constantly looking back at Books Online trying to make sure data types in my tables don’t contain any of those restricted data types. It would be much easier to know from day one which tables I need to redesign, or at least which columns I need to exclude from a non-clustered Columnstore index. This is why I have created the following...
Continue reading...Columnstore Memory Grant Issue
In a previous post about non-clustered columnstore indexes, I mentioned the creation of an index is a very memory intensive operation. Sometimes the memory grant needed exceeds what is currently available on your server. So what do you do about it? SQL Server requires a minimal amount of memory in order to create a columnstore index. This can be calculated as Memory Grant Request in MB = ((4.2 * number of columns in the columnstore index) + 68) * Degree of Parallelism + (number of string columns * 34). If there is not enough physical memory available to create the...
Continue reading...Comparison of Columnstore Compression

SQL Server 2012 introduced non-clustered columnstore indexes, and SQL Server 2014 gave us clustered columnstore indexes. Both share the same technology for performance boosts, and they both share the same algorithms for compression. However, the compression will depend on the data you are storing. SQL Server uses a mechanism of row groups, segments, encoding and compression to store the data for columnstore indexes. First the data is horizontally divided into row groups, where each group contains approximately 1 million rows. Next, the row groups are vertically partitioned into segments, where each column of the table is its own segment. Those...
Continue reading...
