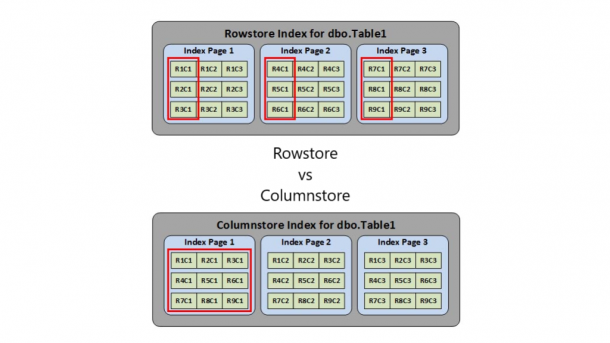
First introduced in SQL Server 2012, the Columnstore index is a new in-memory feature that allows for the creation of indexes that are stored in a column-wise fashion. It is targeted for data warehouses and can improve query performance by 10 to 100x. A columnstore index stores data in a different type of index page as well as heavily compressing the data. It also introduces a new batch execution mode that greatly increases processing speed and reduces CPU utilization. The combination of the new storage type, the compressed data, and batch mode processing allows SQL Server to read less data...
Continue reading...April 2014
The system_health Extended Event Session

When I first started poking around in SQL Server 2012, I noticed an extended event session called “system_health” was created by default. It took me a few months before I really dug into the session details to see what it was capturing. But once I did, I was pretty amazed. The system_health session starts up by default and collects various performance points that can be used to help troubleshoot issues on the server. To look at the details of it, just right click on the event session and choose properties. This will open the Extended Events UI. Select the events...
Continue reading...
